Introduction to Integration Flows
An Integration Flow is a step-by-step movement of a message, which originates from an endpoint in the role of a consumer. The message then flows through a processing component, which could be an EIP or a component. The message is finally sent to a target endpoint that’s in the role of a producer. During routing, messages flow from one processor to another; as such, you can think of an Integration Flow as a graph having specialized processors as the nodes, and lines that connect the output of one processor to the input of another.
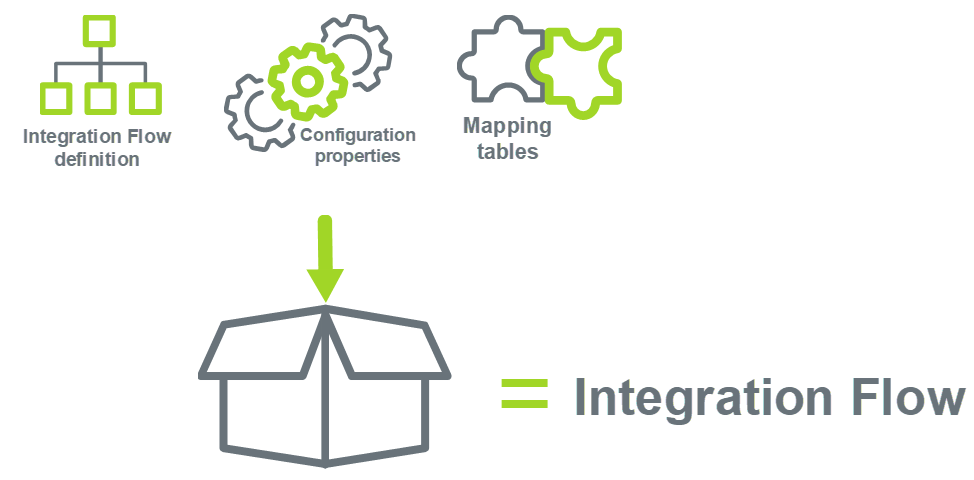
An Integration Flow consists of an Integration Flow definition file, metadata file (containing Configuration Properties and Mapping Table definitions) and supporting files: - Integration Flow Definition: An Integration Flow definition can be designed in an Integration Flow designer (e.g. JBoss Fuse). Under the hood the Integration Flow as designed is formatted and saved as Camel Spring XML. This is called the Integration Flow Definition, which will be further explained in Integration Flow Definition. Tenant specific configuration for an Integration Flow is defined with placeholders in the Integration Flow XML. To be able to use tenant specific configuration in an Integration Flow XML definition, you first need to define the configuration properties. - Configuration properties: To make an Integration Flow reusable and generic, all properties that are tenant-specific have to be marked as tenant-specific configuration properties in the Integration Flow. Each configuration property has to be provided with metadata (e.g. name, type, default value) to ensure that proper values can be filled in during deployment and that validation of configuration values can be applied. Under the hood, configuration properties for an Integration Flow are saved as JSON configuration metadata. This is further explained in sub-item Integration Flow Configuration Properties Metadata. - Mapping tables: To make transformations that are applied within an Integration Flow reusable and generic, mapping tables can be applied via Content Enrichment functions. Each mapping table must be designed when creating the Integration Flow. E.g. name, key columns and value columns must be defined with specific configuration properties so that @deployment time the values in rows can be validated. Under the hood, mapping tables for an Integration Flow are saved as JSON mapping table metadata. How to setup mapping table definitions is further explained in sub-item Integration Flow Mapping Table definitions. - Supporting files: All supporting files used in the Integration Flow, e.g. XSLTs, XSDs etcetera.
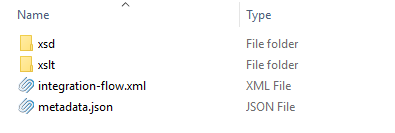
Per Integration Flow version these files are compressed into a zip file which can be published via U4IK portal. The zip file must at least an Integration Flow definition file (integration-flow.xml) and metadata file (metadata.json). Furthermore it can contain subfolders for supporting files, for example a subfolder with xsd's and/or a subfolder with xslt's:
Integration Flow Management
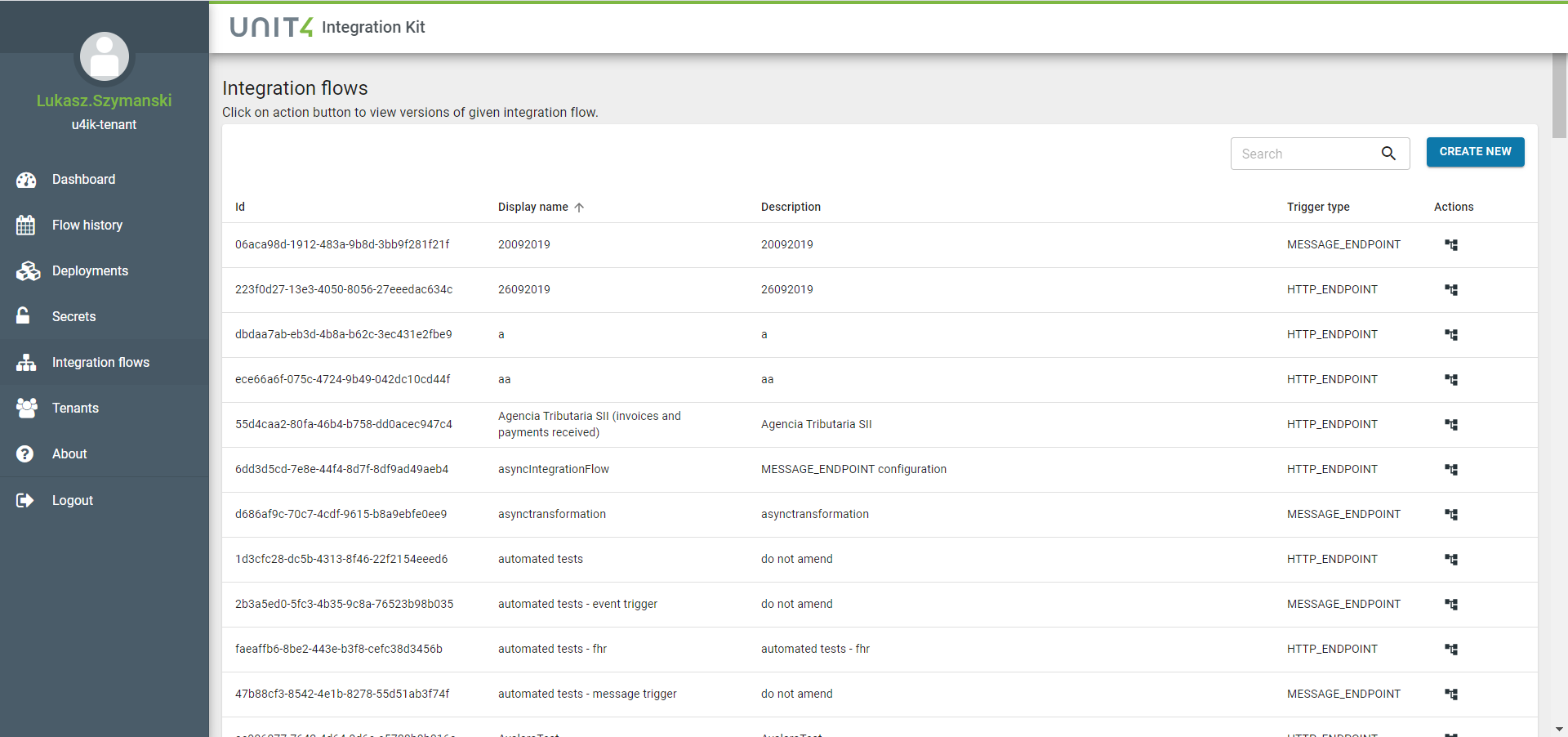
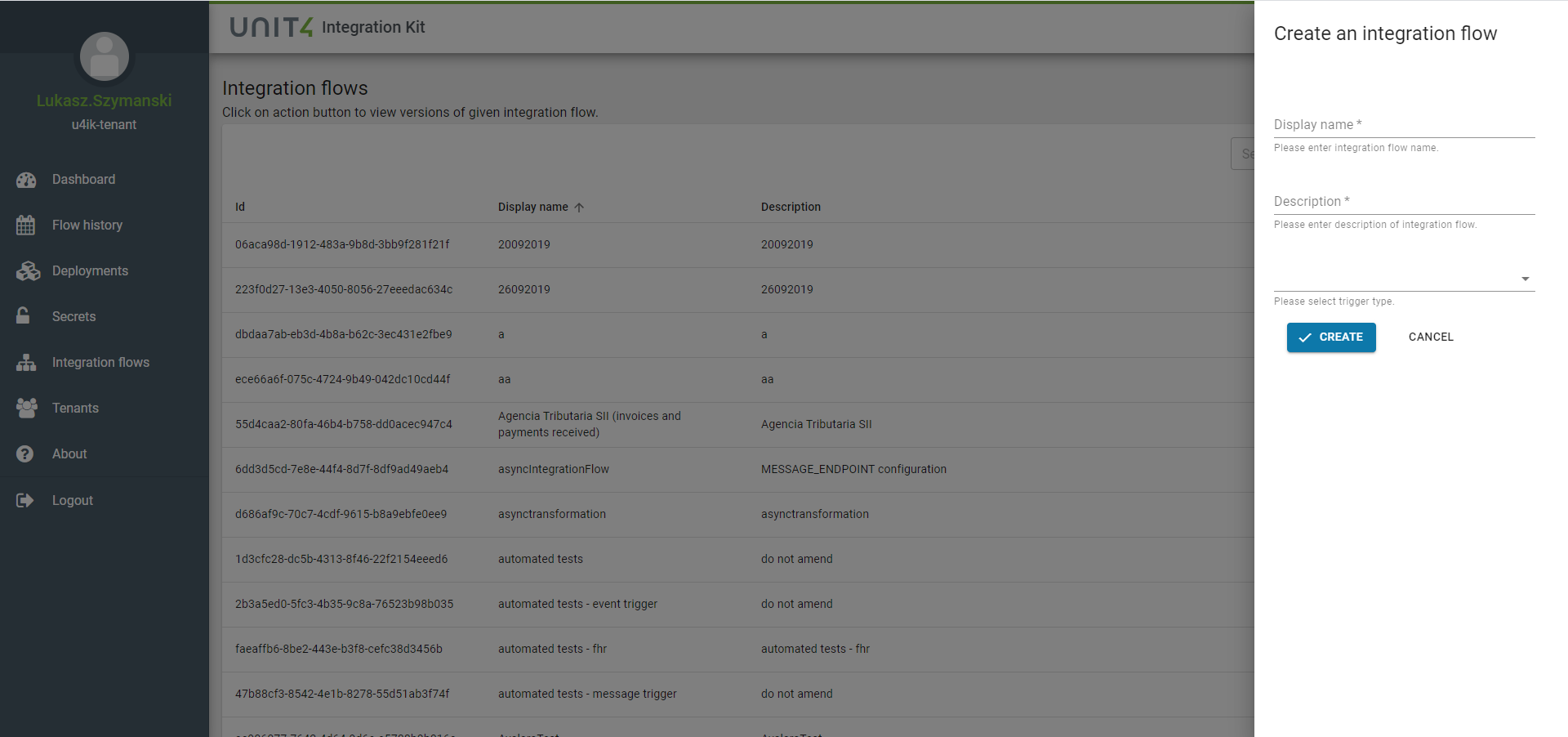
To create a new Integration Flow, you have to choose Integration flows in main menu of U4IK portal. Then the list of existing Integration Flows will be shown with the possibility to create a new Integration Flow:
When you create a new Integration Flow, you have to provide a display name, description and a trigger type. This is just creating a "project" for this Integration Flow:
Under this "project" you can upload new Integration Flow versions. You first have to select the Integration Flow for which you want to upload a new version. The list of corresponding existing versions will be shown:
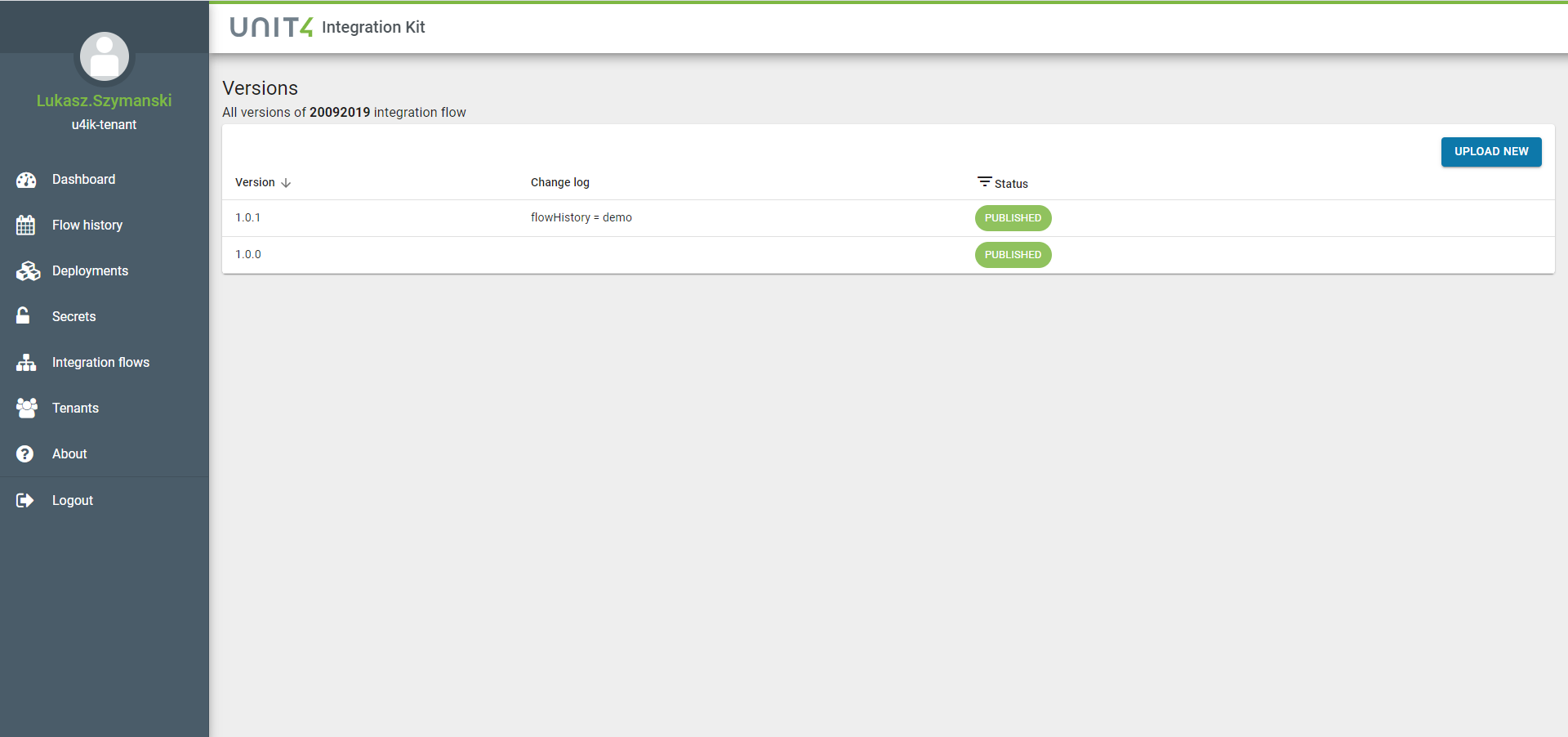
If you want to upload a new Integration Flow version, you have to provide a zip file containing at least an Integration Flow definition and metadata file: